

Clad is a Clang plugin that enables automatic differentiation for C++ by transforming abstract syntax trees using LLVM’s compiler infrastructure. A key design goal is generating readable, efficient derivatives that integrate seamlessly into existing codebases. This talk explores the challenges of extending Clad to support object-oriented programming, demonstrating our approach through examples such as constructors, methods, and non-copyable types. We discuss the analyses and optimization techniques—both implemented and in development—that maintain code readability and performance when handling OOP paradigms. Finally, we present examples of use cases that these enhancements enable.


The compiler research group pioneered interactive C++ notebooks with xeus-clang-repl, and its successor xeus-cpp. The ability to write automatic differentiation code in an interactive context eliminates the need for long edit-compile-run cycles and simplifies the approach to teaching computational methods.
By leveraging the clang-repl C/C++ interpreter, we create an interactive notebook environment for teaching autodiff concepts and evaluating the efficiency and correctness of differentiated code. This approach combines the performance of compiled C++ with the accessibility of Jupyter notebooks, making advanced automatic differentiation techniques more approachable for students and researchers.
This talk demonstrates how various C++ automatic differentiation tools, such as CoDiPack, Clad and boost-autodiff integrate with the xeus-cpp Jupyter kernel to enable interactive differentiable programming.


CAR T-cell therapy has revolutionized cancer immunotherapy by reprogramming patient T cells to recognize and eliminate malignant cells, achieving remarkable success in hematologic cancers. However, its application to solid tumors remains challenging due to the complexity and heterogeneity of the tumor microenvironment.
CARTopiaX is an advanced agent-based model developed on BioDynaMo, an open-source, high-performance platform for large-scale biological simulations that incorporates ROOT. The model enables detailed exploration of interactions between CAR T-cells and solid tumor microenvironments, supporting hypothesis testing and data-driven discovery.
By combining biological accuracy with computational efficiency and scalability, CARTopiaX provides researchers with a powerful tool to investigate CAR T-cell dynamics in silico, accelerating scientific progress and reducing reliance on costly and time-consuming experimental approaches.




The compiler-research.org initiative aims to make compiler research more visible, interconnected, and sustainable across academia and industry. Beyond research infrastructure, it pioneers a new model for open-source education and mentorship offering remote, project-based training in advanced compiler and systems engineering for early-career professionals. This approach fills a critical gap in scientific software development by fostering deep technical mentorship, alignment with research goals, and long-term engagement through meaningful open-source contributions. Graduates emerge ready for research-driven roles in AI, high-performance computing, and scientific software engineering.
This talk will present an overview of the project’s goals and evolving open-source architecture for organizing compiler knowledge in a community-driven way. We’ll explore how foundational compiler and systems tools foster modern data science; highlight recent achievements and ongoing collaborations; and share our vision for enabling cross-disciplinary progress through shared infrastructure and open, connected research.
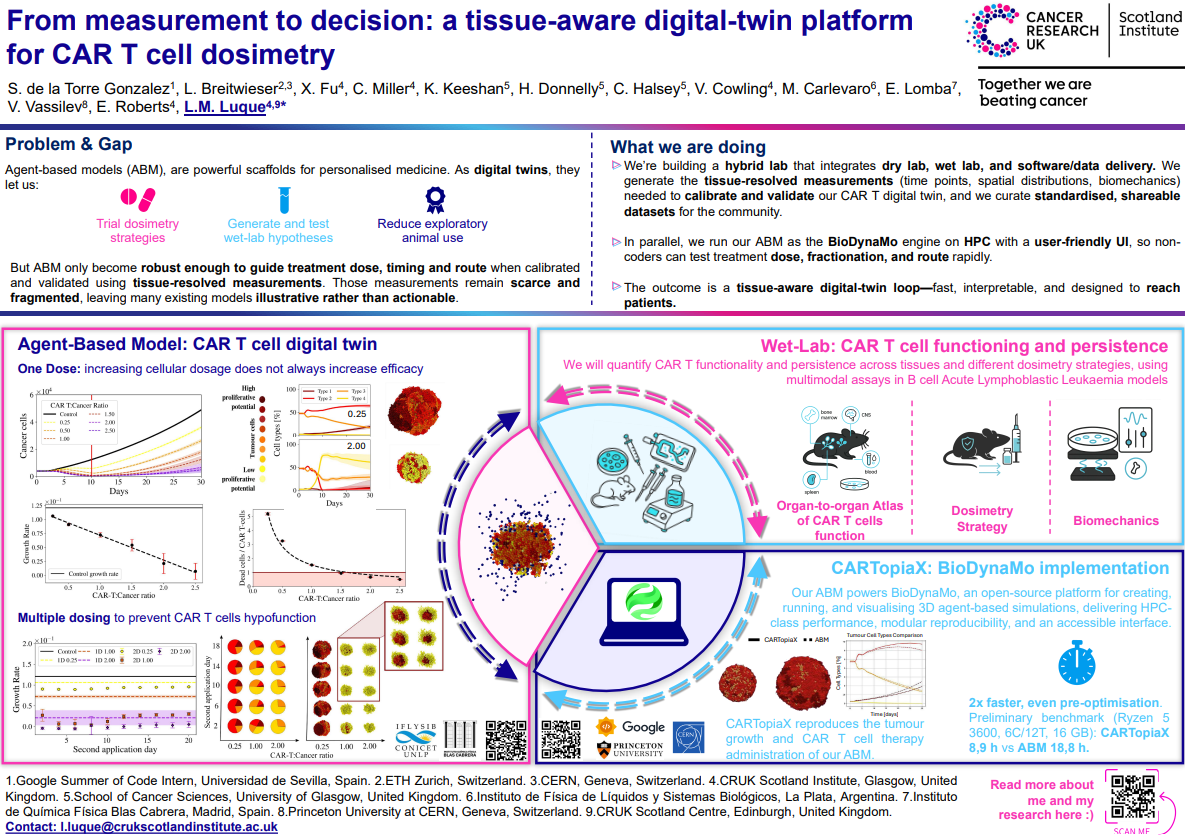
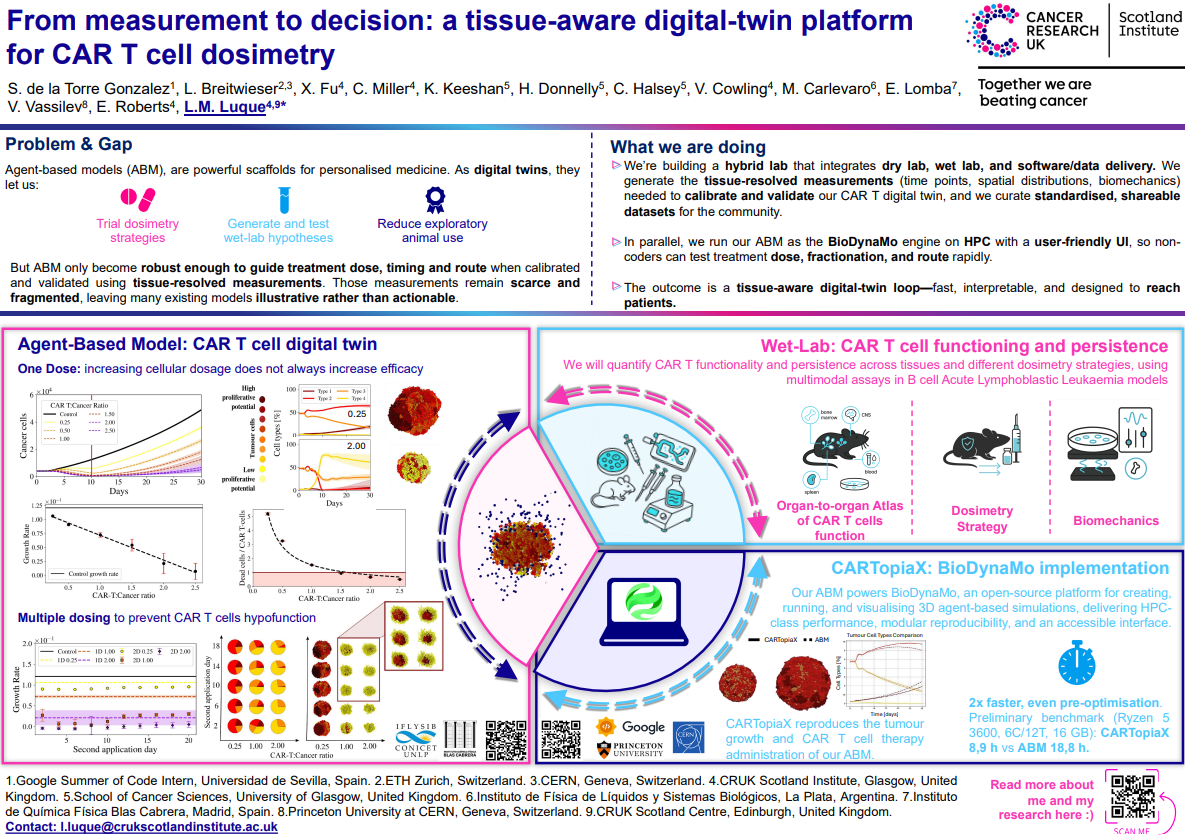
Agent-based models (ABM) are powerful tools for digital twins in personalised medicine, enabling simulation of CAR T cell dynamics and therapy responses. CARTopiaX, implemented in the BioDynaMo engine, supports rapid, high-performance 3D simulations of tumour growth and CAR T cell administration, reproducing cellular dynamics with high fidelity and offering an accessible interface to explore treatment dose, fractionation, and administration routes.
Tissue-resolved wet-lab measurements of CAR T cell functionality and persistence across organs are critical to guide and validate ABM, supporting the evaluation of different dosimetry strategies, including single and multiple dosing to prevent T cell hypofunction. Preliminary benchmarks show that CARTopiaX runs simulations in approximately half the time of the previously published ABM.
This tissue-aware digital-twin framework provides fast, interpretable, and actionable insights, facilitating hypothesis testing, reducing exploratory animal use, and guiding CAR T cell dosimetry in preclinical studies.


RooFit’s integration with the Clad infrastructure has introduced automatic differentiation (AD), leading to significant speedups and driving major improvements in its minimization framework. Besides, the AD integration has also inspired several optimizations and simplifications of key RooFit components in general. The AD framework in RooFit is designed to be extensible, providing all necessary primitives to efficiently traverse RooFit’s computation graphs.
CMS Combine, the primary statistical analysis tool in the CMS experiment, has played a pivotal role in groundbreaking discoveries, including the Higgs boson. Built on RooFit, CMS Combine is making AD a natural extension to improve performance and usability. Recognizing this potential, we have begun a collaborative effort to bridge gaps between the two frameworks with a core focus of enabling AD within CMS Combine through RooFit.
In this talk, we will present our progress, highlight the challenges encountered, and discuss the benefits and opportunities that AD integration brings to the CMS analysis workflow. By sharing insights from our ongoing work, we aim to engage the community in furthering AD adoption in high-energy physics.


GPUs have become increasingly popular for their ability to perform parallel operations efficiently, driving interest in General-Purpose GPU Programming. Scientific computing, in particular, stands to benefit greatly from these capabilities. However, parallel programming systems such as CUDA introduce challenges for code transformation tools due to their reliance on low-level hardware management primitives. These challenges make implementing automatic differentiation (AD) for parallel systems particularly complex.
CUDA is being widely adopted as an accelerator technology in many scientific algorithms from machine learning to physics simulations. Enabling AD for such codes builds a new valuable capability necessary for advancing scientific computing.
Clad is an LLVM/Clang plugin for automatic differentiation that performs source-to-source transformation by traversing the compiler’s internal high-level data structures, and generates a function capable of computing derivatives of a given function at compile time. In this talk, we explore how we recently extended Clad to support GPU kernels and functions, as well as kernel launches and CUDA host functions. We will discuss the underlying techniques and real-world applications in scientific computing. Finally, we will examine current limitations and potential future directions for GPU-accelerated differentiation.


Software systems have grown to millions lines of code and are developed by a community of hundreds of developers. Often benign changes can trigger undesired behavior which is very challenging to isolate and reproduce. The conventional approach to addressing these regressions is time-consuming, usually requiring the expertise of experienced engineers.
Differential debugging is a technique designed to streamline the debugging process by utilizing a previous version of the system as a baseline. This method reduces debugging time and complexity by narrowing down the phase space for bug localization. However, the current practice of differential debugging involves running two instances of the debugger independently, lacking cross communication regarding the execution state.
In this presentation, we introduce a new tool called Interactive Differential Debugging (IDD). IDD automates the process of filtering out irrelevant execution paths between a reference and a regressed software system. Our debugging infrastructure goes beyond identification, providing syntactic and semantic tools to systematically compare the execution states of two versions of the same software, identifying functional or performance regressions. IDD seamlessly integrates with LLDB, leveraging its debug server to collect execution information from both systems. The result is a focused display of debugger states that differ between the two versions. Through practical demonstrations, we illustrate how IDD helps the detection of regressions at scale such as the clang compiler.


The goal of the talk is to demonstrate automatic differentiation in scientific workflows


Kokkos is a high-performance library allowing scientists to develop performance-portable C++ code capable of running on CPUs, GPUs and exotic hardware. The Kokkos infrastructure enables researchers to write generic code for libraries, frameworks, and scientific simulations such as climate simulation tools like Albany and HOMMEXX that can later be run on a large scale on any supercomputing hardware without code rewrites.
Kokkos enables differentiable programming using operator overloading tool, Sacado, which records and executes the linearised computation graph. On the other side of the tool spectrum is Clad. It uses the source transformation approach to AD where more advanced optimisations can be investigated. For Kokkos, Clad brings reverse mode support and increased scalability. The challenge with source transformation tools is incorporating framework-specific knowledge and expressing the analytical primitives specific to the framework.
In this talk, we discuss how Clad works and enables AD for large domain-specific frameworks such as Kokkos. We describe how Clad handles support for the C++ STL as another example of its flexibility. We explain extension points such as user-defined custom derivatives, which allow derivatives of Kokkos constructs to be expressed in terms of themselves, without falling back to precise hardware-dependent definitions. We delve into the specifics of the process and lessons learned while integrating Clad with Kokkos and show results demonstrating how Clad has facilitated efficient and scalable automatic differentiation with Kokkos.


Clad is a LLVM/Clang plugin designed to provide automatic differentiation (AD) for C++ mathematical functions. It generates code for computing derivatives modifying abstract syntax tree using LLVM compiler features. Clad supports forward- and reverse-mode differentiation that are effectively used to integrate all kinds of functions. The typical AD approach in Machine Learning tools records and flattens the compute graph at runtime, whereas Clad can perform more advanced optimizations at compile time using a rich program representation provided by the Clang AST. These optimizations investigate which parts of the computation graph are relevant to the AD rules.
One such technique is the “To-Be-Recorded” optimization, which reduces the memory pressure to the clad tape data structure in the adjoint mode. Another optimization technique is activity analysis, which discards all derivative statements that are not relevant to the generated code. In the talk we will explain compiler-level optimizations specific to AD, and will show some specific examples of how these analyses have impacted clad applications.


With the growing datasets of HEP experiments, statistical analysis becomes more computationally demanding, requiring improvements in existing statistical analysis software. One way forward is to use Automatic Differentiation (AD) in likelihood fitting, which is often done with RooFit (a toolkit that is part of ROOT.) As of recently, RooFit can generate the gradient code for a given likelihood function with Clad, a compiler-based AD tool. At the CHEP 2023, and ICHEP 2024 conferences, we showed how using this analytical gradient significantly speeds up the minimization of simple likelihoods. This talk will present the current state of AD in RooFit. One highlight is that it now supports more complex models like template histogram stacks (“HistFactory”). It also uses a new version of Clad that contains several improvements tailored to the RooFit use case. This contribution will furthermore demo complete RooFit workflows that benefit from the improved performance with AD, such as CMS and ATLAS Higgs measurements.


In this presentation, we will delve into the innovative world of Clad, an automatic differentiation (AD) tool designed for C++. We introduce the Clad programming model and highlight the advantages of employing transformation-based automatic differentiation within high-performance static languages like C++. Through practical examples, we demonstrate how Clad can be leveraged at scale.
Our discussion will also focus on the integration of AD into RooFit, a toolkit extensively utilized in high-energy physics and nuclear physics experiments for statistical modeling. We showcase how the new AD backend effectively extracts differentiable properties from decades-old infrastructure, resulting in enhanced performance and numeric stability during likelihood minimizations.
One of the key aspects of our approach is the development of a generic methodology to transform the object-oriented compute graph within RooFit into overhead-free C++ code, making it amenable to AD. This transformation enables us to apply AD to large production workflows consisting of hundreds of thousands of lines of scientific codes. Furthermore, we will illustrate that AD emerges as the preferred choice for workflows involving numerous parameters. It leads to reduced minimization times, faster overall fit convergence by minimizing fit iterations, and improved accuracy in gradient calculations.


Built upon Clang and LLVM incremental compilation pipelines, Clang-Repl is
a C++ interpreter featuring a REPL that enables C++ users to develop
programs in an exploratory fashion. Autocompletion in Clang-Repl is a
significant leap forward in this direction. The feature empowers Clang-Repl
to accelerate their input and prevent typos. Inspired by the counterpart
feature in Cling, a downstream project of Clang-Repl, our auto-completion
feature leverages existing components of Clang/LLVM, and provides
context-aware semantic completion suggestions. In this talk, we will present
how autocompletion works at REPL and how it interacts with other Clang/LLVM
infrastructure.


In many ways Python and C++ represent the two ends in the spectrum of programming languages. C++ has an important role in the field of computing as the language design principles promote efficiency, reliability and backward compatibility – a vital tripod for any long-lived codebase. Python has prioritized better usability and safety while making some tradeoffs on efficiency and backward compatibility. That has led developers to believe that there is a binary choice between performance and usability.
Python has become the language of data science and machine learning in particular while C++ still is the language of voice for performance-critical software. The C++ and Python ecosystems are vast and achieving seamless interoperability between them is essential to avoid risky software rewrites.
In this talk we leverage our decade-old experience in writing automatic Python to C++ bindings. We demonstrate how we could connect the Python interpreter to the new in-tree C++ interpreter called Clang-Repl. We show how we can build a uniform execution environment between both languages using the new compiler-as-a-service (CaaS) API available in Clang. The execution environment enables advanced interoperability such as the ability for Python to instantiate C++ templates on demand, inherit from C++ classes or catch std::exception. We show how CaaS can be connected to external services such as Jupyter and execute code written in both languages.


One of the prominent applications of the JIT compiler is the ability to compile “hot” functions utilizing various runtime profiling metrics gathered by slow versions of functions. The ORC API can be generalized further to make use of the profiling metrics and “reoptimize” the function hiding the reoptimization latency. For instance, one of the many applications of this technique is to compile functions at a lower optimization level for faster compilation speed and then reoptimize them to a higher level when those functions are frequently executed. This talk we demonstrate how we can express lazy JIT, speculative compilation, and re-optimization as “symbol redirection” problems. We demonstrate the improved ORC API for redirecting symbols. In addition, this technical talk will peek at internal details of how we implemented re-optimization support and showcase the demos such as real time clang-repl re-optimization from -O0 to -O3 or real time virtual call optimization through de-virtualization.


The C++ programming language is used for many numerically intensive scientific applications. A combination of performance and solid backward compatibility has led to its use for many research software codes over the past 20 years. Despite its power, C++ is often seen as difficult to learn and inconsistent with rapid application development. Exploration and prototyping is slowed down by the long edit-compile-run cycles during development.
In this talk we show how to leverage our experience in interactive C++, just-in-time compilation technology (JIT), dynamic optimizations, and large scale software development to greatly reduce the impedance mismatch between C++ and Python. We show how clang-repl generalizes Cling in LLVM upstream to offer a robust, sustainable and omnidisciplinary solution for C++ language interoperability. The demonstrate how we have:
The presentation includes interactive session where we demonstrate some of the capabilities of our system via the Jupyter interactive environment.


The simplicity of Python and the power of C++ force stark choices on a scientific software stack. There have been multiple developments to mitigate language boundaries by implementing language bindings, but the impedance mismatch between the static nature of C++ and the dynamic one of Python hinders their implementation; examples include the use of user-defined Python types with templated C++ and advanced memory management.
The development of the C++ interpreter Cling has changed the way we can think of language bindings as it provides an incremental compilation infrastructure available at runtime. That is, Python can interrogate C++ on demand, and bindings can be lazily constructed at runtime. This automatic binding provision requires no direct support from library authors and offers better performance than alternative solutions, such as PyBind11. ROOT pioneered this approach with PyROOT, which was later enhanced with its successor, cppyy. However, until now, cppyy relied on the reflection layer of ROOT, which is limited in terms of provided features and performance.
The next step for language interoperability with cppyy, enabling research into uniform cross-language execution environments and boosting optimization opportunities across language boundaries. We illustrate the use of advanced C++ in Numba-accelerated Python through cppyy. We outline a path forward for re-engineering parts of cppyy to use upstream LLVM components to improve performance and sustainability. We demonstrate cppyy purely based on a C++ reflection library, InterOp, which offers interoperability primitives based on Cling and Clang-Repl.
Based on our recent publication: https://arxiv.org/abs/2304.02712
We can share more details about the efforts done within the compiler-research project in the area of mixing python and C++ in a single jupyter notebook via technologies such as xeus-clang-repl.


In this talk, we present our efforts in supporting Automatic Differentiation (AD) in RooFit, a toolkit for statistical modeling and fitting used by many HEP/NP experiments that is part of ROOT. The new AD backend improves both the performance and numeric stability of likelihood minimizations, for which we will provide several examples in this contribution. Our approach is to extend RooFit with a tool that generates overhead-free C++ code for a full likelihood function built from RooFit functional models. Gradients are then generated using Clad, a compiler-based source-code-transformation AD tool, using this C++ code. After presenting promising results from a proof-of-concept with this pipeline applied to a HistFactory model at the ACAT 2022 conference, we showcased more general benchmarks on the full minimization pipeline at CHEP 2023. In this workshop, we present how AD can be applied to production workflows in the field of HEP/NP. We also demonstrate that AD is the prime choice for workflows with many parameters, yielding lower minimization times and faster overall fit convergence due to lesser fit iterations and improved accuracy of the calculated gradients.


Clad enables automatic differentiation (AD) for C++. It is based on LLVM compiler infrastructure and is a plugin for Clang compiler. Clad is based on source code transformation. Given C++ source code of a mathematical function, it can automatically generate C++ code for computing derivatives of the function. Clad supports a large set of C++ features including control flow statements and function calls. It supports reverse-mode AD (a.k.a backpropagation) as well as forward-mode AD. It also facilitates computation of hessian matrix and jacobian matrix of any arbitrary function.
In this talk we describe the programming model that Clad enables. We explain what are the benefits of using transformation-based automatic differentiation in high-performance static languages such as C++. We show examples of how to use the tool at scale.


In this talk, we report on the effort to support automatic differentiation (AD) in RooFit, a toolkit for statistical modeling and fitting used by many HEP/NP experiments that is part of ROOT. The new AD backend improves both the performance and numeric stability of likelihood minimizations, for which we will provide several examples in this contribution. Our approach is to extend RooFit with a tool that generates overhead-free C++ code for a full likelihood function built from RooFit functional models. Gradients are then generated using Clad, a compiler-based source-code-transformation AD tool, using this C++ code. After presenting promising results from a proof-of-concept with this pipeline applied to a HistFactory model at the ACAT 2022 conference, we reported on the integration inside ROOT and showcased more general benchmarks at CHEP 2023. Following this last milestone, work focused on evolving the Minuit 2 minimizer backed to make better use of the automatic gradient and extended the code generation with support for more RooFit models. In this workshop, we will present updated benchmarks where all numeric differentiation is avoided on the Minuit 2 side, as well as new results with the RooFit AD backed applied to cutting-edge ATLAS Higgs analysis benchmarks for the first time.
These results show that the RooFit AD backend is the prime choice for combined binned likelihoods with many parameters, yielding minimization times one order of magnitude below RooFits other backends and improving the fit convergence rate.


As we reach the limit of Moore’s Law, researchers are exploring different paradigms to achieve unprecedented performance. Approximate Computing (AC), which relies on the ability of applications to tolerate some error in the results to trade-off accuracy for performance, has shown significant promise. Despite the success of AC in domains such as Machine Learning, its acceptance in High-Performance Computing (HPC) is limited due to its stringent requirement of accuracy. We need tools and techniques to identify regions of the code that are amenable to approximations and their impact on the application output quality so as to guide developers to employ selective approximation. To this end, we propose CHEF-FP, a flexible, scalable, and easy-to-use source-code transformation tool based on Automatic Differentiation (AD) for analysing approximation errors in HPC applications.
CHEF-FP uses Clad, an efficient AD tool built as a plugin to the Clang compiler and based on the LLVM compiler infrastructure, as a backend and utilizes its AD abilities to evaluate approximation errors in C++ code. CHEF-FP works at the source level by injecting error estimation code into the generated adjoints. This enables the error-estimation code to undergo compiler optimizations resulting in improved analysis time and reduced memory usage. We also provide theoretical and architectural augmentations to source code transformation-based AD tools to perform FP error analysis.
In this talk, we primarily focus on analyzing errors introduced by mixed-precision AC techniques, the most popular approximate technique in HPC. We also show the applicability of our tool in estimating other kinds of errors by evaluating our tool on codes that use approximate functions. Moreover, we demonstrate the speedups achieved by CHEF-FP during analysis time as compared to the existing state-of-the-art tool as a result of its ability to generate and insert approximation error estimate code directly into the derivative source. The generated code also becomes a candidate for better compiler optimizations contributing to lesser runtime performance overhead.


With the growing datasets of current and next-generation High-Energy and Nuclear Physics (HEP/NP) experiments, statistical analysis has become more computationally demanding. These increasing demands elicit improvements and modernizations in existing statistical analysis software. One way to address these issues is to improve parameter estimation performance and numeric stability using automatic differentiation (AD). AD’s computational efficiency and accuracy is superior to the preexisting numerical differentiation techniques and offers significant performance gains when calculating the derivatives of functions with a large number of inputs, making it particularly appealing for statistical models with many parameters. For such models, many HEP/NP experiments use RooFit, a toolkit for statistical modeling and fitting that is part of ROOT.
In this talk, we report on the effort to support the AD of RooFit likelihood functions. Our approach is to extend RooFit with a tool that generates overhead-free C++ code for a full likelihood function built from RooFit functional models. Gradients are then generated using Clad, a compiler-based source-code-transformation AD tool, using this C++ code. We present our results from applying AD to the entire minimization pipeline and profile likelihood calculations of several RooFit and HistFactory models at the LHC-experiment scale. We show significant reductions in calculation time and memory usage for the minimization of such likelihood functions. We also elaborate on this approach’s current limitations and explain our plans for the future.


Over the last decade the C++ programming language has evolved significantly into safer, easier to learn and better supported by tools general purpose programming language capable of extracting the last bit of performance from bare metal. The emergence of technologies such as LLVM and Clang have advanced tooling support for C++ and its ecosystem grew qualitatively. C++ has an important role in the field of scientific computing as the language design principles promote efficiency, reliability and backward compatibility - a vital tripod for any long-lived codebase. Other ecosystems such as Python have prioritized better usability and safety while making some tradeoffs on efficiency and backward compatibility. That has led developers to believe that there is a binary choice between performance and usability.
In this talk we would like to present the advancements in the C++ ecosystem; its relevance for scientific computing and beyond; and foreseen challenges. The talk introduces three major components for data science - interpreted C++; automatic language bindings; and differentiable programming. We outline how these components help Python and C++ ecosystems interoperate making a little compromise on either performance or usability. We elaborate on a future hybrid Python/C++ differentiable programming analysis framework which might accelerate science discovery in HEP by amplifying the power and physics sensitivity of data analyses into end-to-end differentiable pipelines.


RooFit is a toolkit for statistical modeling and fitting used by most experiments in particle physics. Just as data sets from next-generation experiments grow, processing requirements for physics analysis become more computationally demanding, necessitating performance optimizations for RooFit. One possibility to speed-up minimization and add stability is the use of automatic differentiation (AD). Unlike for numerical differentiation, the computation cost scales linearly with the number of parameters, making AD particularly appealing for statistical models with many parameters. In this talk, we report on one possible way to implement AD in RooFit. Our approach is to add a facility to generate C++ code for a full RooFit model automatically. Unlike the original RooFit model, this generated code is free of virtual function calls and other RooFit-specific overhead. In particular, this code is then used to produce the gradient automatically with Clad. Clad is a source transformation AD tool implemented as a plugin to the clang compiler, which automatically generates the derivative code for input C++ functions. We show results demonstrating the improvements observed when applying this code generation strategy to HistFactory and other commonly used RooFit models.
HistFactory is the subcomponent of RooFit that implements binned likelihood models with probability densities based on histogram templates. These models frequently have a very large number of free parameters, and are thus an interesting first target for AD support in RooFit.


The simplicity of Python and the power of C++ provide a hard choice for a scientific software stack. There have been multiple developments to mitigate the hard language boundaries by implementing language bindings. The static nature of C++ and the dynamic nature of Python are problematic for bindings provided by library authors and in particular features such as template instantiations with user-defined types or more advanced memory management.
The development of the C++ interpreter Cling has changed the way we can think of language bindings as it provides an incremental compilation infrastructure available at runtime. That is, Python can interrogate C++ on demand and fetch only the necessary information. This way of automatic binding provision requires no binding support by the library authors and offers better performance than Pybind11. This approach pioneered in ROOT with PyROOT and later was enhanced with its successor Cppyy. However, until now, Cppyy relied on the reflection layer of ROOT which is limited in terms of provided features and performance.
In this talk we show how basing Cppyy purely on Cling yields better correctness, performance and installation simplicity. We illustrate more advanced language interoperability of Numba-accelerated Python code capable of calling C++ functionality via Cppyy. We outline a path forward for integrating the reflection layer in LLVM upstream which will contribute to the project sustainability and will foster greater user adoption. We demonstrate usage of Cppyy through Cling’s LLVM mainline version Clang-Repl


The scientific community using Python has developed several ways to accelerate Python codes. One popular technology is Numba, a Just-in-time (JIT) compiler that translates a subset of Python and NumPy code into fast machine code using LLVM. We have extended Numba’s integration with LLVM’s intermediate representation (IR) to enable the use of C++ kernels and connect them to Numba accelerated codes. Such a multilanguage setup is also commonly used to achieve performance or to interface with external bare-metal libraries. In addition, Numba users will be able to write the performance-critical codes in C++ and use them easily at native speed.
This work relies on high-performance, dynamic, bindings between Python and C++. Cppyy, which is the basis of PyROOT’s interfaces to C++ libraries. Cppyy uses Cling, an incremental C++ interpreter, to generate on-demand bindings of required entities and connect them with the Python interpreter. This environment is uniquely positioned to enable the use of C++ from Numba in a fast and automatic way.
In this talk, we demonstrate using C++ from Numba through Cppyy. We show our approach which extends Cppyy to match the object typing and lowering models of Numba and the necessary additions to the reflection layers to generate IR from Python objects. The uniform LLVM runtime allows optimizations such as inlining which can in the future remove the C++ function call overhead. We discuss other optimizations such as lazily instantiated C++ templates based on input data. The talk also briefly outlines the non-negligible, Numba-introduced JIT overhead and possible ways to optimize it. Since this is built as a Cppyy extension Numba supports all bindings automatically without any user intervention.


Automatic Differentiation is a powerful technique to evaluate the derivative of a function specified by a computer program. Thanks to the ROOT interpreter, Cling, this technique is available in ROOT for computing gradients and Hessian matrices of multi-dimensional functions. We will present the current integration of this tool in the ROOT Mathematical libraries for computing gradients of functions that can then be used in numerical algorithms. For example, we demonstrate the correctness and performance improvements in ROOT’s fitting algorithms. We will show also how gradient and Hessian computation via AD is integrated in the main ROOT minimization algorithm Minuit. We will show also the present plans to integrate the Automatic Differentiation in the RooFit modelling package for obtaining gradients of the full model that can be used for fitting and other statistical studies.


Floating-point errors are a testament to the finite nature of computing and if left uncontrolled they can have catastrophic results. As such, for high-precision computing applications, quantifying these uncertainties becomes imperative. There have been significant efforts to mitigate such errors by either extending the underlying floating-point precision, using alternate compensation algorithms or estimating them using a variety of statistical and non-statistical methods. A prominent method of dynamic floating-point error estimation is using Automatic Differentiation (AD). However, most state-of-the-art AD-based estimation software requires manually adapting or annotating the source code by some amount. Moreover, operator overloading AD based error estimation tools call for multiple gradient recomputations to report errors over a large variety of inputs and suffer from all the shortcomings of the underlying operator overloading strategy such as reduced efficiency. In this work, we propose a customizable way to use AD to synthesize source code for estimating uncertainties arising from floating-point arithmetic in C/C++ applications.
Our work presents an automatic error annotation framework that can be used in conjunction with custom user defined error models. We also present our progress with error estimation on GPU applications.


Automatic Differentiation (AD) is instrumental for science and industry. It is a tool to evaluate the derivative of a function specified through a computer program. The range of AD application domain spans from Machine Learning to Robotics to High Energy Physics. Computing gradients with the help of AD is guaranteed to be more precise than the numerical alternative and have at most a constant factor (4) more arithmetical operations compared to the original function. Moreover, AD applications to domain problems typically are computationally bound. They are often limited by the computational requirements of high-dimensional transformation parameters and thus can greatly benefit from parallel implementations on graphics processing units (GPUs).
Clad aims to enable differentiable analysis for C/C++ and CUDA and is a compiler-assisted AD tool available both as a compiler extension and in ROOT. Moreover, Clad works as a compiler plugin extending the Clang compiler; as a plugin extending the interactive interpreter Cling; and as a Jupyter kernel extension based on xeus-cling.
In this talk, we demonstrate the advantages of parallel gradient computations on graphics processing units (GPUs) with Clad. We explain how to bring forth a new layer of optimisation and a proportional speed up by extending the usage of Clad for CUDA. The gradients of well-behaved C++ functions can be automatically executed on a GPU. Thus, across the spectrum of fields, researchers can reuse their existing models and have workloads scheduled on parallel processors without the need to optimize their computational kernels. The library can be easily integrated into existing frameworks or used interactively, and provides optimal performance. Furthermore, we demonstrate the achieved application performance improvements, including (~10x) in ROOT histogram fitting and corresponding performance gains from offloading to GPUs.


The design of LLVM and Clang enables them to be used as libraries, and has led to the creation of an entire compiler-assisted ecosystem of tools. The relatively friendly codebase of Clang and advancements in the JIT infrastructure in LLVM further enable research into different methods for processing C++ by blurring the boundary between compile time and runtime. Challenges include incremental compilation and fitting compile/link time optimizations into a more dynamic environment.
Incremental compilation pipelines process code chunk-by-chunk by building an ever-growing translation unit. Code is then lowered into the LLVM IR and subsequently run by the LLVM JIT. Such a pipeline allows creation of efficient interpreters. The interpreter enables interactive exploration and makes the C++ language more user friendly. The incremental compilation mode is used by the interactive C++ interpreter, Cling, initially developed to enable interactive high-energy physics analysis in a C++ environment. Cling is now used for interactive development in Jupyter Notebooks (via xeus-cling), dynamic python bindings (via cppyy) and interactive CUDA development.
In this talk we dive into the details of implementing incremental
compilation with Clang. We outline a path forward for Clang-Repl which is
built with the experience gained in Cling and is now available in mainstream
llvm. We describe how the new Orc JIT infrastructure allows us to naturally
perform static optimizations at runtime, and enables linker voodoo to make
the compiler/interpreter boundaries disappear. We explain the potential of
having a compiler-as-a-service architecture in the context of automatic
language interoperability for Python and beyond.


Clad enables automatic differentiation (AD) for C++ algorithms through source-to-source transformation. It is based on LLVM compiler infrastructure and as a Clang compiler plugin. Different from other tools, Clad manipulates the high-level code representation (the AST) rather than implementing its own C++ parser and does not require modifications to existing code bases. This methodology is both easier to adopt and potentially more performant than other approaches. Having full access to the Clang compiler’s internals means that Clad is able to follow the high-level semantics of algorithms and can perform domain-specific optimisations; automatically generate code (re-targeting C++) on accelerator hardware with appropriate scheduling; and has a direct connection to compiler diagnostics engine and thus producing precise and expressive diagnostics positioned at desired source locations.
In this talk, we showcase the above mentioned advantages through examples and outline Clad’s features, applications and support extensions. We describe the challenges coming from supporting automatic differentiation of broader C++ and present how Clad can compute derivatives of functions, member functions, functors and lambda expressions. We show the newly added support of array differentiation which provides the basis utility for CUDA support and parallelisation of gradient computation. Moreover, we will demo different interactive use-cases of Clad, either within a Jupyter environment as a kernel extension based on xeus-cling or within a gpu-cpu environment where the gradient computation can be accelerated through gpu-code produced by Clad and run with the help of the Cling interpreter.


C++ is used for many numerically intensive applications. A combination of performance and solid backward compatibility has led to its use for many research software codes over the past 20 years. Despite its power, C++ is often seen as difficult to learn and not well suited with rapid application development. The long edit-compile-run cycle is a large impediment to exploration and prototyping during development.
Cling has emerged as a recognized capability that enables interactivity, dynamic interoperability and rapid prototyping capabilities for C++ developers. Cling is an interactive C++ interpreter, built on top of the Clang and LLVM compiler infrastructure. The interpreter enables interactive exploration and makes the C++ language more welcoming for research. Cling supports the full C++ feature set including the use of templates, lambdas, and virtual inheritance.Cling’s field of origin is the field of high energy physics where it facilitates the processing of scientific data. The interpreter was an essential part of the software tools of the LHC experimental program and was part of the software used to detect the gravitational waves of the LIGO experiment. Interactive C++ has proven to be useful for other communities. The Cling ecosystem includes dynamic bindings tools to languages including python, D and Julia (cppyy); C++ in Jupyter Notebooks (xeus-cling); interactive CUDA; and automatic differentiation on the fly (clad).
This talk outlines key properties of interactive C++ such as execution results, entity redefinition, error recovery and code undo. It demonstrates the capability enabled by an interactive C++ platform in the context of data science. For example, the use of eval-style programming, C++ in Jupyter notebooks and CUDA C++. We talk about design and implementation challenges and go beyond just interpreting C++. We showcase template instantiation on demand, language interoperability on demand and bridging compiled and interpreted code. We show how to easily build new capabilities using the Cling infrastructure through developing an automatic differentiation plugin for C++ and CUDA.


Mathematical derivatives are vital components of many computing algorithms including: neural networks, numerical optimization, Bayesian inference, nonlinear equation solvers, physics simulations, sensitivity analysis, and nonlinear inverse problems. Derivatives track the rate of change of an output parameter with respect to an input parameter, such as how much reducing an individuals’ carbon footprint will impact the Earth’s temperature. Derivatives (and generalizations such as gradients, jacobians, hessians, etc) allow us to explore the properties of a function and better describe the underlying process as a whole. In recent years, the use of gradient-based optimizations such as training neural networks have become widespread, leading to many languages making differentiation a first-class citizen.
Derivatives can be computed numerically, but unfortunately the accumulation of floating-point errors and high-computational complexity presents several challenges. These problems become worse with higher order derivatives and more parameters to differentiate.
Many derivative-based algorithms require gradients, or the computation of the derivative of an output parameter with respect to many input parameters. As such, developing techniques for computing gradients that are scalable in the number of input parameters is crucial for the performance of such algorithms. This paper describes a broad set of domains where scalable derivative computations are essential. We make an overview of the major techniques in computing derivatives, and finally, we introduce the flagman of computational differential calculus – algorithmic (also known as automatic) differentiation (AD). AD makes clever use of the ‘nice’ mathematical properties of the chained rule and generative programming to solve the scalability issues by inverting the dependence on the number of input variables to the number of output variables. AD provides mechanisms to augment the regular function computation with instructions calculating its derivatives.
Differentiable programming is a programming paradigm in which the programs can be differentiated throughout, usually via automatic differentiation. This talk introduces the differentiable programming paradigm in terms of C++. It shows its applications in science as applicable for data science and industry. The authors make an overview of the existing tools in the area and the two common implementation approaches – template metaprogramming and custom parsers. We demonstrate implementation pros and cons and propose compiler toolchain-based implementation either in clang AST or LLVM IR. We would like to briefly outline our current efforts in standardization of that feature.
<b>Differentiating Object-Oriented paradigms using Clad</b> <br />
<em>Petro Zarytskyi </em> at the [28th EuroAD Workshop](https://indico.cern.ch/event/1543104/contributions/6791593/) (9 December 2025) [Link to Slides](/assets/presentations/Petro_Clad_EuroAD_2025.pdf)
<b>Teaching Automatic Differentiation with Interactive C++ Jupyter Notebooks</b> <br />
<em>Aaron Jomy </em> at the [28th EuroAD Workshop](https://indico.cern.ch/event/1543104/contributions/6791578/) (9 December 2025) [Link to Slides](/assets/presentations/Aaron_Teaching_EuroAD_2025.pdf)
<b>CARTopiaX: an Agent-Based Simulation of CAR T-Cell Therapy built with BioDynaMo and ROOT</b> <br />
<em>Salvador de la Torre Gonzalez </em> at the [ROOT Users CERN's Workshop 2025 in UPV-Valencia](https://indico.cern.ch/event/1505384/contributions/6781575/) (21 November 2025) [Link to Slides](/assets/presentations/Salva_ROOT_Valencia_CARTopiaX_2025.pdf)
<b>Advancing Python-C++ Interoperability in ROOT and beyond </b> <br />
<em>Aaron Jomy, Vipul Nellamakada </em> at the [ROOT Users CERN's Workshop 2025 in UPV-Valencia](https://indico.cern.ch/event/1505384/contributions/6781575/) (20 November 2025) [Link to Slides](/assets/presentations/Aaron_Vipul_ROOT_Valencia_InterOp_2025.pdf)
<b>Compiler Research in the Open: Connecting People, Projects, and Progress</b> <br />
<em>Vassil Vassilev </em> at the [ROOT Users CERN's Workshop 2025 in UPV-Valencia](https://indico.cern.ch/event/1505384/contributions/6781575/) (18 November 2025) [Link to Slides](/assets/presentations/Vassil_ROOT_Valencia_CR_2025.pdf)
<b>From measurement to decision: a tissue-aware digital-twin platform for CAR T cell dosimetry</b> <br />
<em>Luciana Melina Luque </em> at the [Foundations of Oncological Digital Twins workshop in Cambridge](https://www.newton.ac.uk/event/ooew07/) (19 September 2025) [Link to Poster](/assets/presentations/LMLuque_Poster_19_09_2025.pdf)
<b>Scaling RooFit's Automatic Differentiation Capabilities to CMS Combine</b> <br />
<em>Vassil Vasilev </em> at the [Mode 2025](https://indico.cern.ch/event/1481852/contributions/6464892) (11 June 2025) [Link to Slides](/assets/presentations/Vassil_CladRooFit_Mode2025.pdf)
<b>Bringing Automatic Differentiation to CUDA with Compiler-Based Source Transformations</b> <br />
<em>Christina Koutsou </em> at the [Mode 2025](https://indico.cern.ch/event/1481852/contributions/6491917/) (11 June 2025) [Link to Slides](/assets/presentations/Christina_CladCudaAD_Mode2025.pdf)
<b>Debugging Regressions: Interactive Differential Debugging</b> <br />
<em>Vipul Cariappa, Martin Vassilev </em> at the [EuroLLVM 2025](https://youtu.be/sI-jxB0tGpM?si=CNNo264OvA4JMqRb) (16 April 2025) [Link to Slides](/assets/presentations/Vipul__Martin_EuroLLVM2025_IDD.pdf)
<b>Automatic Differentiation in RooFit and Community Needs</b> <br />
<em>Vassil Vasilev </em> at the [Foundation Models for Science Mini Workshop](https://indico.cern.ch/event/1459124/contributions/6155024/) (1 October 2024) [Link to Slides](/assets/presentations/Vassil_CladRooFit_FoundSci2024.pdf)
<b>Automatic Differentiation of the Kokkos framework and the STL with Clad</b> <br />
<em>Atell Yehor Krasnopolski </em> at the [Fourth MODE Workshop](https://indico.cern.ch/event/1380163/) (25 September 2024) [Link to Slides](/assets/presentations/Krasnopolsky-2024-MODE-clad-STL-kokkos.pdf)
<b>Advanced optimizations for source transformation based automatic differentiation</b> <br />
<em>Maksym Andriichuk </em> at the [MODE 2024](https://indico.cern.ch/event/1380163/) (25 September 2024) [Link to Slides](/assets/presentations/Maksym_Andriichuk_MODE2024_Optimizations.pdf)
<b>Automatic Differentiation in RooFit</b> <br />
<em>Vassil Vassilev </em> at the [MODE 2024](https://indico.cern.ch/event/1380163/) (25 September 2024) [Link to Slides](/assets/presentations/assets/presentations/V_Vassilev-MODE2024_CladRooFit.pdf)
<b>Improving BioDynamo's Performance using ROOT C++ Modules</b> <br />
<em>Isaac Morales Santana </em> at the [Fourth MODE Workshop](https://indico.cern.ch/event/1380163/) (24 September 2024) [Link to poster](/assets/presentations/Fourth_MODE_Isaac_Morales.pdf)
<b>Accelerating Large Scientific Workflows Using Source Transformation Automatic Differentiation</b> <br />
<em>Vassil Vassilev </em> at the SNL (16 October 2023) [Link to Slides](/assets/presentations/V_Vassilev-SNL_Accelerating_Large_Workflows_Clad.pdf)
<b>Code-Completion in Clang-Repl</b> <br />
<em>Yuquan (Fred) Fu </em> at the [LLVM 2023](https://llvm.swoogo.com/2023devmtg/agenda) (12 October 2023) [Link to Slides](/assets/presentations/Y_Fu-LLVMDev23_ClangReplAutoComplete.pdf)
<b>Unlocking the Power of C++ as a Service: Uniting Python's Usability with C++'s Performance</b> <br />
<em>Vassil Vassilev </em> at the [LLVM 2023](https://llvm.swoogo.com/2023devmtg/agenda) (12 October 2023) [Video](https://youtu.be/rdfBnGjyFrc), [Link to Slides](/assets/presentations/V_Vassilev-LLVMDev23_CppPython.pdf)
<b>Automatic program reoptimization support in LLVM ORC JIT</b> <br />
<em>Sunho Kim </em> at the [LLVM 2023](https://llvm.swoogo.com/2023devmtg/agenda) (11 October 2023) [Video](https://youtu.be/2ST0Rz_pC58), [Link to Slides](/assets/presentations/S_Kim-LLVMDev23_Automatic_Program_Reopt.pdf)
<b>C++ as a service - rapid software development and dynamic interoperability with python and beyond</b> <br />
<em>Vassil Vassilev </em> at the [Compiler-Research Monthly 2023](https://compiler-research.org/meetings/#caas_20Sep2023) (20 September 2023) [Video](https://youtu.be/be89sF0WLrc), [Link to Slides](/assets/presentations/V_Vassilev-CaaS_ShowCase.pdf)
<b>Automatic Interoperability Between C++ and Python</b> <br />
<em>Baidyanath Kundu </em> at the [PyHEP.Dev 2023](https://indico.cern.ch/event/1234156/contributions/5504654/) (25 July 2023) [Link to Slides](/assets/presentations/B_Kundu-PyHEP23_Cppyy_CppInterOp.pdf)
<b>Making Likelihood Calculations Fast Using Automatic Differentiation in RooFit</b> <br />
<em>Garima Singh </em> at the [MODE 2023](https://indico.cern.ch/event/1242538/) (25 July 2023) [Link to Slides](/assets/presentations/G_Singh-MODE3_Fast_Likelyhood_Calculations_RooFit.pdf)
<b>Efficient C++ Derivatives Through Source Transformation AD With Clad</b> <br />
<em>Vassil Vassilev </em> at the [MODE 2023](https://indico.cern.ch/event/1242538/) (25 July 2023) [Link to Slides](/assets/presentations/V_Vassilev-MODE2023_Efficient_Cpp_Derivatives_Clad.pdf)
<b>Adding Automatic Differentiation to RooFit</b> <br />
<em>Garima Singh </em> at the [The Road to Differentiable and Probabilistic Programming in Fundamental Physics 2023](https://indico.ph.tum.de/event/7113) (27 June 2023) [Link to Slides](/assets/presentations/G_Singh-MiapbTUM_AD_RooFit.pdf)
<b>Fast And Automatic Floating Point Error Analysis With CHEF-FP</b> <br />
<em>Baidyanath Kundu </em> at the [IPDPS 2023](https://www.ipdps.org/ipdps2023/) (18 May 2023) [Link to Slides](/assets/presentations/IPDPS23-Estimating_Floating_Point_Errors.pdf)
<b>Making Likelihood Calculations Fast: Automatic Differentiation Applied to RooFit</b> <br />
<em>Garima Singh </em> at the [CHEP 2023](https://indico.jlab.org/event/459/) (8 May 2023) [Link to Slides](/assets/presentations/Garima_Singh_AD_RooFIt_CHEP_2023.pdf)
<b>RooFit-AD Plan of Work</b> <br />
<em>Garima Singh </em> at the Weekly Compiler Research Meetings (1 February 2023) [Link to slides](/assets/presentations/RooFitADPlanofWork_01_02_23.pdf)
<b>Adapting C++ for Data Science</b> <br />
<em>Vassil Vassilev </em> at the [ACAT 2022](https://indico.cern.ch/event/1106990/) (28 October 2022) [Link to slides](/assets/presentations/VV-ACAT2022-AdaptingCppforDataScience.pdf)
<b>Automatic Differentiation of Binned Likelihoods With RooFit and Clad</b> <br />
<em>Garima Singh </em> at the [ACAT 2022](https://indico.cern.ch/event/1106990/) (26 October 2022) [Link to slides](/assets/presentations/GS-ACAT2022-AutomaticDifferentiationofBinnedLikelihoodswithRooFitandClad.pdf)
<b>Efficient and Accurate Automatic Python Bindings with Cppyy and Cling</b> <br />
<em>Baidyanath Kundu </em> at the [ACAT 2022](https://indico.cern.ch/event/1106990/) (25 October 2022) [Link to slides](/assets/presentations/BK-ACAT2022-AutomaticPythonBindingswithCppyyandCling.pdf)
<b>Using C++ From Numba, Fast and Automatic</b> <br />
<em>Baidyanath Kundu </em> at the [PyHEP 2022](https://indico.cern.ch/event/1150631/) (16 September 2022) [Video](https://www.youtube.com/watch?v=RceFPtB4m1I), [Link to notebook](/assets/presentations/B_Kundu-PyHEP22_Cppyy_Numba.pdf)
<b>Automatic Differentiation in ROOT</b> <br />
<em>Garima Singh </em> at the [MODE AD Workshop 2022](https://indico.cern.ch/event/1145124/contributions/) (14 September 2022) [Link to slides](/assets/presentations/GS-MODEAD2022-AutomaticDifferentiationinROOT.pdf)
<b>A numba extension for cppyy / PyROOT</b> <br />
<em>Baidyanath Kundu </em> at the [Parallelism, Performance and Programming model meeting](https://indico.cern.ch/e/PPP140) (1 September 2022) [Slides](https://indico.cern.ch/event/1196174/contributions/5028203/attachments/2501253/4296778/PPP.pdf), [Notebook](https://indico.cern.ch/event/1196174/contributions/5028203/attachments/2501253/4296735/PPP.ipynb)
<b>CSSI Element: C++ as a service - rapid software development and dynamic interoperability with Python and beyond</b> <br />
<em>David Lange </em> at the [2022 NSF CSSI PI meeting](https://cssi-pi-community.github.io/2022-meeting) (26 July 2022) [Link to slides](/assets/presentations/CSSI_lange_poster_20202_printed.pdf)
<b>Estimating Floating-Point Errors Using Automatic Differentiation</b> <br />
<em>Vassil Vassilev, Garima Singh </em> at the [SIAM UQ 2022](https://www.siam.org/conferences/cm/conference/uq22) (14 April 2022) [Video](https://www.youtube.com/watch?v=pndnawFPKHA&list=PLeZvkLnDkqbS8yQZ6VprODLKQVdL7vlTO&index=8), [Link to slides](/assets/presentations/G_Singh-SIAMUQ22_FP_Error_Estimation.pdf)
<b>GPU Acceleration of Automatic Differentiation in C++ with Clad</b> <br />
<em>Ioana Ifrim </em> at the [ACAT 2021](https://indico.cern.ch/event/855454) (30 November 2021) [Video](https://videos.cern.ch/record/2295042), [Link to slides](/assets/presentations/I_Ifrim-ACAT21_GPU_AD.pdf)
<b>Enabling Interactive C++ with Clang</b> <br />
<em>Vassil Vassilev </em> at the [LLVM Developers' Meeting 2021](https://llvm.swoogo.com/2021devmtg/) (17 November 2021) [Video](https://youtu.be/33ncbIQoa4c), [Link to slides](/assets/presentations/V_Vassilev-LLVMDev21_InteractiveCpp.pdf)
<b>Enabling Interactive C++ with Clang</b> <br />
<em>Ioana Ifrim </em> at the [24th EuroAD Workshop 2021](http://www.autodiff.org/?module=Workshops&submenu=EuroAD%2F24%2Fprogramme) (4 November 2021) [Link to slides](/assets/presentations/I_Ifrim-EuroAD21_GPU_AD.pdf)
<b>Interactive C++ for Data Science</b> <br />
<em>Vassil Vassilev </em> at the [CppCon21](https://cppcon.org/program2021/) (27 October 2021) [Video](https://youtu.be/23E0S3miWB0), [Link to slides](/assets/presentations/V_Vassilev-CppCon21_InteractiveCpp.pdf)
<b>Differentiable Programming in C++</b> <br />
<em>William Moses, Vassil Vassilev </em> at the [CppCon21](https://cppcon.org/program2021/) (26 October 2021) [Video](https://youtu.be/1QQj1mAV-eY), [Link to slides](/assets/presentations/W_Moses_V_Vassilev-CppCon21_DifferentiableProgrammingInCpp.pdf)
<b>Add support for differentiating functors</b> <br />
<em>Parth Arora </em> at the [IRIS-HEP GSoC presentations meeting](https://indico.cern.ch/event/1066812/) (1 September 2021) [presentation](https://indico.cern.ch/event/1066812/contributions/4485920/attachments/2301761/3915402/IRIS-HEP-Add-support-for-differentiating-functors-presentation.pdf), [Poster](/assets/presentations/add-support-for-differentiating-functors-poster.pdf)
<b>Utilise Second Order Derivatives from Clad in ROOT</b> <br />
<em>Baidyanath Kundu </em> at the [IRIS-HEP GSoC presentations meeting](https://indico.cern.ch/event/1066812/) (1 September 2021) [Link to slides](https://indico.cern.ch/event/1066812/contributions/4509414/attachments/2301766/3915408/Utilize%20second%20order%20derivatives%20from%20Clad%20in%20ROOT.pdf)
<b>Add Numerical Differentiation Support To Clad</b> <br />
<em>Garima Singh </em> at the [IRIS-HEP GSoC presentations meeting](https://indico.cern.ch/event/1066812/) (1 September 2021) [Link to slides](https://indico.cern.ch/event/1066812/contributions/4495279/attachments/2301763/3915404/Numerical%20Differentiaition%20.pdf)
<b>GPU Acceleration of Automatic Differentiation in C++ with Clad</b> <br />
<em>Ioana Ifrim </em> at the [IRIS-HEP topical meeting](https://indico.cern.ch/event/1040761/) (21 June 2021) [Link to slides](https://indico.cern.ch/event/1040761/contributions/4400258/attachments/2268253/3851595/Ioana%20Ifrim%20-%20GPU%20Acceleration%20of%20Automatic%20Differentiation%20in%20C%2B%2B%20with%20Clad.pdf)
<b>Floating point error estimation using Clad -- Final Report</b> <br />
<em>Garima Singh </em> at the [IRIS-HEP topical meeting](https://indico.cern.ch/event/1040761/) (21 June 2021) [Link to slides](https://indico.cern.ch/event/1040761/contributions/4371613/attachments/2268248/3851583/floating_point_error_est.pdf)
<b>Floating point error estimation using Clad -- Project Roadmap</b> <br />
<em>Garima Singh </em> at the Onboarding meetup (15 December 2020) [pdf](/assets/presentations/ErrorEstimationWithClad_15_12_2020.pdf), [pptx](/assets/presentations/ErrorEstimationWithClad_15_12_2020.pptx)
<b>Adding CUDA® Support to Cling: JIT Compile to GPUs</b> <br />
<em>Simeon Ehrig </em> at the [2020 LLVM workshop](https://llvm.org/devmtg/2020-09/) (8 October 2020) [Link to slides and video](https://zenodo.org/record/4021877)
<b>Incremental Compilation Support in Clang</b> <br />
<em>Vassil Vassilev </em> at the [2020 LLVM workshop](https://llvm.org/devmtg/2020-09/) (7 October 2020) [Link to poster](/assets/presentations/LLVM2020_CaaS.pdf)
<b>Error estimates of floating-point numbers and Jacobian matrix computation in Clad</b> <br />
<em>Vassil Vassilev </em> at the [2020 LLVM workshop](https://llvm.org/devmtg/2020-09/) (7 October 2020) [Link to poster](/assets/presentations/LLVM2020_Clad.pdf)
<b>Enabling C++ Modules for ROOT on Windows</b> <br />
<em>Vaibhav Garg </em> at the [IRIS-HEP topical meeting](https://indico.cern.ch/event/950229/) (8 September 2020) [Link to slides](/assets/presentations/WinCXXModules_31_08_2020.pdf)
<b>Modernizing Boost in CMSSW</b> <br />
<em>Lukas Camolezi </em> at the [IRIS-HEP topical meeting](https://indico.cern.ch/event/945364) (2 September 2020) [Link to slides](https://indico.cern.ch/event/945364/contributions/3992254/attachments/2095731/3522488/cmssw-finalpresentation.pdf)
<b>Clad -- Automatic Differentiation in C++ and Clang</b> <br />
<em>Vassil Vassilev </em> at the [23rd Euro AD workshop](http://www.autodiff.org/?module=Workshops&submenu=EuroAD/23/main) (11 August 2020) [Link to talk](http://www.autodiff.org/Docs/euroad/23rd%20EuroAd%20Workshop%20-%20Vassil%20Vassilev%20-%20Clad%20--%20Automatic%20Differentiation%20in%20C++%20and%20Clang.pdf)
<b>CaaS slide for 2020 NSF CSSI PI meeting</b> <br />
<em>David Lange </em> at the [2020 NSF CSSI meeting, Seattle, WA](https://cssi-pi-community.github.io/2020-meeting) (13 February 2020) [Link to slides](/assets/presentations/CSSI2020_slide.pdf)
<b>CaaS poster for 2020 NSF CSSI PI meeting</b> <br />
<em>David Lange </em> at the [2020 NSF CSSI meeting, Seattle, WA](https://cssi-pi-community.github.io/2020-meeting) (13 February 2020) [Link to poster](/assets/presentations/CSSI2020_poster.pdf)
<b>Automatic Differentiation in C++</b> <br />
<em>Vassil Vassilev and Marco Foco (NVIDIA) </em> at the Prague 2020 ISO C++ WG21 meeting (10 February 2020) [Link to slides](/assets/presentations/CladInROOT_15_02_2020.pdf)
<b>C++ Modules in ROOT and Beyond</b> <br />
<em>Oksana Shadura </em> at the [2019 CHEP International Conference](chep2019.org) (7 November 2019) [Link to slides](https://indico.cern.ch/event/773049/contributions/3473264/attachments/1937517/3215659/C_Modules_in_ROOT_and_Beyond4.pdf)
<b>Automatic Differentiation in ROOT</b> <br />
<em>Oksana Shadura </em> at the [Computing in High Energy Physics (CHEP 2019, Adeliade)](http://chep2019.org) (5 November 2019) [Link to slides](https://indico.cern.ch/event/773049/contributions/3474747/attachments/1935465/3212004/Automatic_Differentiation_in_ROOT3.pdf)
<b>Clad - Clang plugin for Automatic Differentiation</b> <br />
<em>J Qiu </em> at the [IRIS-HEP Topical meeting](https://indico.cern.ch/event/840376) (21 August 2019) [Link to slides](https://indico.cern.ch/event/840376/contributions/3527105/attachments/1895396/3126873/Clad_-_Clang_plugin_for_Automatic_Differentiation_1.pdf)
<b>Implementation of GlobalModuleIndex in ROOT and Cling</b> <br />
<em>Arpitha Raghunandan </em> at the [IRIS-HEP Topical meeting](https://indico.cern.ch/event/840376) (21 August 2019) [Link to slides](https://indico.cern.ch/event/840376/contributions/3525646/attachments/1895398/3127159/GSoC_Presentation__GMI.pdf)
<b>Clad: the automatic differentiation plugin for Clang</b> <br />
<em>Aleksandr Efremov </em> at the [IRIS-HEP topical meeting](https://indico.cern.ch/event/815976/) (29 May 2019) [Link to slides](https://indico.cern.ch/event/815976/contributions/3405951/attachments/1853315/3043286/CladIRIS.pdf)
<b>Migrating large codebases to C++ Modules</b> <br />
<em>Yuka Takahashi </em> at the [19th International Workshop on Advanced Computing and Analysis Techniques in Physics Research (ACAT 2019 Saas-Fee)](https://indico.cern.ch/event/708041/) (13 March 2019) [Link to slides](https://indico.cern.ch/event/708041/contributions/3276196/attachments/1810525/3007180/ACAT_CModules.pdf)
<b>DIANA-HEP Final Presentation Runtime C++ modules</b> <br />
<em>Yuka Takahashi </em> at the [DIANA-HEP Topical meeting](https://indico.cern.ch/event/798499) (18 February 2019) [Link to slides](https://indico.cern.ch/event/798499/contributions/3318311/attachments/1797966/2931691/DIANA_Yuka_final.pdf)
<b>Future of ROOT runtime C++ modules</b> <br />
<em>Yuka Takahashi </em> at the [ROOT Users Workshop (Sarajevo)](https://indico.cern.ch/event/697389/) (12 September 2018) [Link to slides](https://indico.cern.ch/event/697389/contributions/3062026/attachments/1714046/2764895/Future_of_ROOT_runtime_C_modules.pdf)
<b>Optimizing Frameworks Performance Using C++ Modules-Aware ROOT</b> <br />
<em>Yuka Takahashi </em> at the [Computing in High Energy Physics (CHEP 2018, Sofia)](https://indico.cern.ch/event/587955/) (10 July 2018) [Link to poster](https://indico.cern.ch/event/587955/contributions/2937639/attachments/1679562/2697775/CHEP_poster_third.pdf)
<b>C++ Modules in ROOT</b> <br />
<em>Raphael Isemann </em> at the [DIANA-HEP topical meeting](https://indico.cern.ch/event/682267/) (4 December 2017) [Link to slides](https://indico.cern.ch/event/682267/contributions/2795954/attachments/1569847/2475832/Runtime_C_Modules_presentation.pdf)
<b>ROOT C++ Modules</b> <br />
<em>Raphael Isemann </em> at the [DIANA-HEP topical meeting](https://indico.cern.ch/event/643728/) (17 July 2017) [Link to slides](https://indico.cern.ch/event/643728/contributions/2612822/attachments/1494074/2323893/ROOTs_C_modules_status_report.pdf)

We are partially funded by the
Princeton Department of Physics
and
Princeton Institute for Computational Science and Engineering
(PICSciE).
Contact: David Lange; Vassil Vassilev
This project is supported by the National Science Foundation under Grant OAC-1931408 (2020-2023) and OAC-2311471(2023-2026). Any opinions, findings, conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
© 2019 Princeton University. Site made with Jekyll; Credit to Allan lab for this site template.
