Final report for creating teaching materials with xeus-cpp

Main goals of this project
The main goal of this project was to create interactable examples for the for the CUDA and OpenMP programming models, targeting beginners who want hands-on experience with parallel computing on both the GPU and CPU.
Each notebook builds on the previous one, introducing new concepts gradually through working code examples.
Together the 16 notebooks cover the full beginner to intermediate journey - from launching a first thread to understanding memory hierarchies, synchronisation primitives, and performance optimization on both CPU and GPU.
The CUDA notebooks
The CUDA notebooks include 8 different examples that add to one another. Here is what each one explains:
- The first notebook is a basic introduction to CUDA with simple examples like the global kernel usage and calling it.
- Next we introduce some more fundamental concepts.
- The third notebook shows how using parallel programming can speed up if we use the threads the right way.
- After that we show thread cooperation. The threads split the work instead of having one thread per task
- Then we demonstrate The Julia set. A complex mathematical shape.
- The sixth example creates a ripple pattern.
- Next we demonstrate the dot product. A mathematical operation that takes two equal-length vectors and returns a single regular number
- Lastly there is a simple ray tracing example.
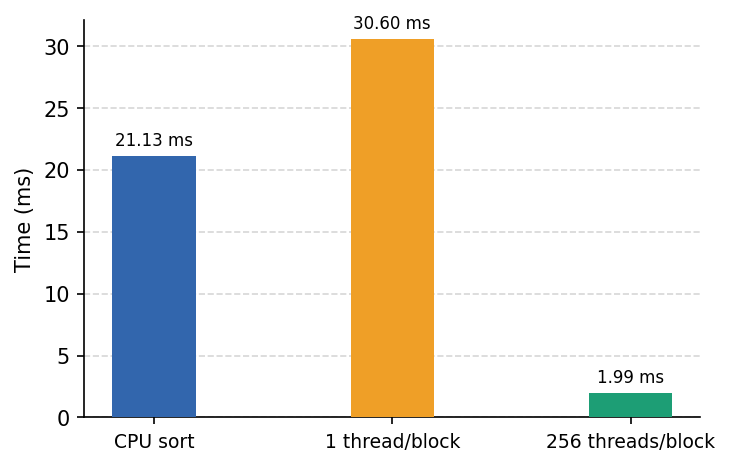
CUDA benchmark vs the CPU
This benchmark adds two vectors with 10 million elements each into a third one. This is done 3 times using different methods.
- The first one is a basic CPU only demonstration. The time is around 21 ms.
- The second example is using the GPU but with only 1 thread per block. We can see that this is slower compared to the first one. This is a very unoptimized way to use the device.
- The third method is now a lot faster than the other 2. We make each block use 256 threads which speeds up the time by a lot - around 2 milliseconds.
The OpenMP notebooks
The OpenMP notebooks also include 8 different examples that add to one another. Here is what each one explains:
- The first notebook is a basic introduction to OpenMP with simple examples like the #pragma omp parallel directive and thread creation.
- Next we introduce the fork-join model and how threads are spawned and joined back together.
- Then we demonstrate the Pi integral. A mathematical problem solved by splitting the work across multiple threads.
- The fourth notebook calculates the area of the Mandelbrot set. A complex mathematical shape rendered in parallel by assigning different regions to different threads.
- After that we show linked list traversal. How pointer-based data structures interact with parallel execution.
- The sixth example demonstrates race conditions. What happens when threads write to the same memory without protection and how to fix it.
- Next we demonstrate false sharing. How threads can slow each other down even when touching different variables due to CPU cache line behaviour.
- Lastly there is Conway’s Game of Life. A grid simulation where threads compute the next generation in parallel using double buffering to avoid race conditions by design.

