Final results of improvements to ramtools

Introduction
My name is Georgi Haralanov and the past couple of months I worked on improving the ramtools query binary by the addition of multithreading. Here are recorded some results and benchmarks of the new code as well as some ideas for the future.
Mentor: Vassil Vassilev
I/O Slowdown
A big part of the slowdown occurred due to a slow opening of the file being read. This was solved by redesigning the way that indexing data is stored and read. With the new indexing table around 4 seconds of read time is cut each query.
Multithreading
The addition of multithreading using the ROOT framework increases efficacy of the tool under significant load. Modern machines on average have 8 cores with some reaching up to 32 logical ones. The addition of multithreading allows the full utilization of all the hardware of a machine.
Thread scaling
For a certain range of active threads a linear relationship is formed between the number of threads and the speed of the query. With the current maximum and meaningful query size, which is one chromosome, the aforementioned range of threads is 1-5, where the time to execute is approximately the time taken by one thread over the number of threads. Any amount above five threads doesn’t lead to an increase of speed.
Benchmarks
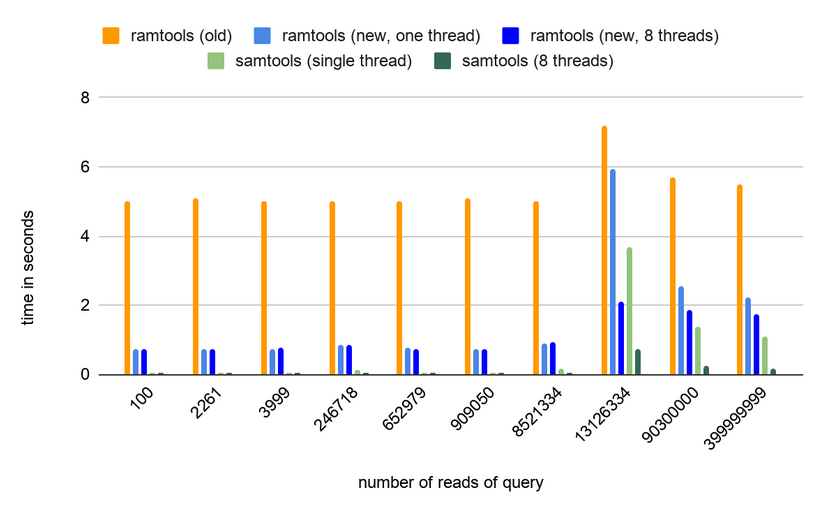 These results were measured using the built-in time utility from Ubuntu.
All of the multithreaded samples were taken with 8 threads to assure the
minimum achievable real time for the tools as mentioned in the thread scaling part
above. They show the increase in speed when comparing the new and the old
implementation but also that samtools seems to use an even more efficient approach
to querying. The speed of the tool shouldn’t be a major bottleneck in the majority
of usecases so any future work on that aspect could be postponed to a later date.
These results were measured using the built-in time utility from Ubuntu.
All of the multithreaded samples were taken with 8 threads to assure the
minimum achievable real time for the tools as mentioned in the thread scaling part
above. They show the increase in speed when comparing the new and the old
implementation but also that samtools seems to use an even more efficient approach
to querying. The speed of the tool shouldn’t be a major bottleneck in the majority
of usecases so any future work on that aspect could be postponed to a later date.
Future Possibilities
Some places which could be researched more include further file format support outside of the current common ones. An alternative to the CRAM file format where only the differences between a sample read and a reference read is stored could be created using the ROOT framework. This approach leads to smaller file sizes but has the downside of needing multiple files for any meaningful operation which clutters up storage and complicates transferal. The same compression approach can be reproduced but storing the reference and the sample reads on one file is possible with the RNTuple file format from ROOT. Using specific or custom compression algorithms for different fields of a read could also lead to a higher compression ratio.

