GSoC 2025 Final: Compiler-Driven LLM Training with Clad and C++


Project Summary
When I began Google Summer of Code 2025, the goal was ambitious: to demonstrate that a C++-centric approach with compile-time Automatic Differentiation could be used for training Large Language Model (LLM) efficiently. The hypothesis was that by using Clad, a Clang plugin for source-to-source AD, we could eliminate the overhead other frameworks and enable deeper compiler optimizations.
This post details the journey from initial concept to a fully functional end-to-end training pipeline. We explore the main technical decisions and results that validate compiler-driven ML as a promising approach for high-performance computing.
Phase 1: The cladtorch Library
Following the initial plan, I built cladtorch, a PyTorch-style tensor library with a clean, object-oriented API. It featured a Tensor class, encapsulation of state, and automatic memory management. We successfully implemented a full GPT-2 forward pass and, critically, achieved our core technical objective: applying clad::gradient to the entire model’s loss function.
// Our target: differentiate the whole model at once
auto grad_fn = clad::gradient(gpt2_loss, "model");
This allows us to write neural networks like this:
// Inside gpt2::LayerNorm
Tensor forward(const Tensor& input) const {
auto norm = input.norm();
auto tmp = norm * weight;
return tmp + bias;
}
Which clad will then automatically write the backpropation pass for via clad::gradient:
void forward_pullback(
const Tensor& input, Tensor _d_y,
gpt2::LayerNorm* _d_this, Tensor* _d_input
) const {
op_plus_pullback(&tmp, this->bias, _d_result, &_d_tmp, &_d_this->bias);
op_star_pullback(&norm, this->weight, _d_tmp, &_d_norm, &_d_this->weight);
norm_pullback(&input, _d_norm, _d_input);
}
Clad successfully processed loops, custom classes, and nested calls to generate the complete backward pass. This alone was a significant validation of Clad’s capabilities. Initial benchmarks were encouraging — we matched the order-of-magnitude performance of Karpathy’s llm.c — but profiling revealed we were still 3-4x slower than PyTorch. The culprit wasn’t matrix multiplication (our BLAS kernels were already optimized), but rather the abstraction overhead of our design: temporary object creation, dynamic memory allocation mid-training, and memory access patterns that weren’t cache-friendly.
Phase 2: Optimized Training Loop
Faced with this overhead, we made a decisive pivot. I rewrote the engine from scratch, trading API familiarity for raw speed. Inspired by llm.c’s simplified approach, the new design was built on two main ideas:
-
Single Memory Arena: One massive, pre-allocated
float*buffer holds all model parameters, gradients, and activations. TheGPT2struct simply contains pointers into this arena. This eliminates all dynamic allocation during training and dramatically improves data locality. -
Stateless Kernels: Every operation (
matmul,layernorm,softmax) became a pure C-style function operating on raw pointers. No classes, no hidden state, no RAII overhead in tight loops: just simple, predictable code that is much easier for the compiler to optimize.
This stateless kernel design turned out to be a great match for Clad. Instead of asking Clad to differentiate complex class methods, we could provide custom derivatives for each simple kernel using clad::custom_derivatives. Clad then orchestrates these hand-optimized pullbacks into the full backward pass.
{Maybe we can rewrite this example to show what clad actually does with the pullback in the vein of the previous example - maybe even the same example just in this style of implementation.}
// The forward kernel: simple and stateless
void layernorm_forward(float* out, float* inp, float* weight, float* bias, int N, int C);
// Custom Derivative registered with Clad
namespace clad::custom_derivatives {
void forward_pullback(...) { /* calls layernorm_forward_pullback */ }
}
This approach gave us the best of both worlds: Clad’s automated, compiler-level orchestration of the backpropagation graph and our manual optimization of the most performance-critical kernels.
Benchmark Results
The results on an Apple M3 Max CPU speak for themselves. We measured the time for a full training iteration (forward + backward pass) for GPT-2 (124M parameters) across different batch sizes (B) and sequence lengths (T).
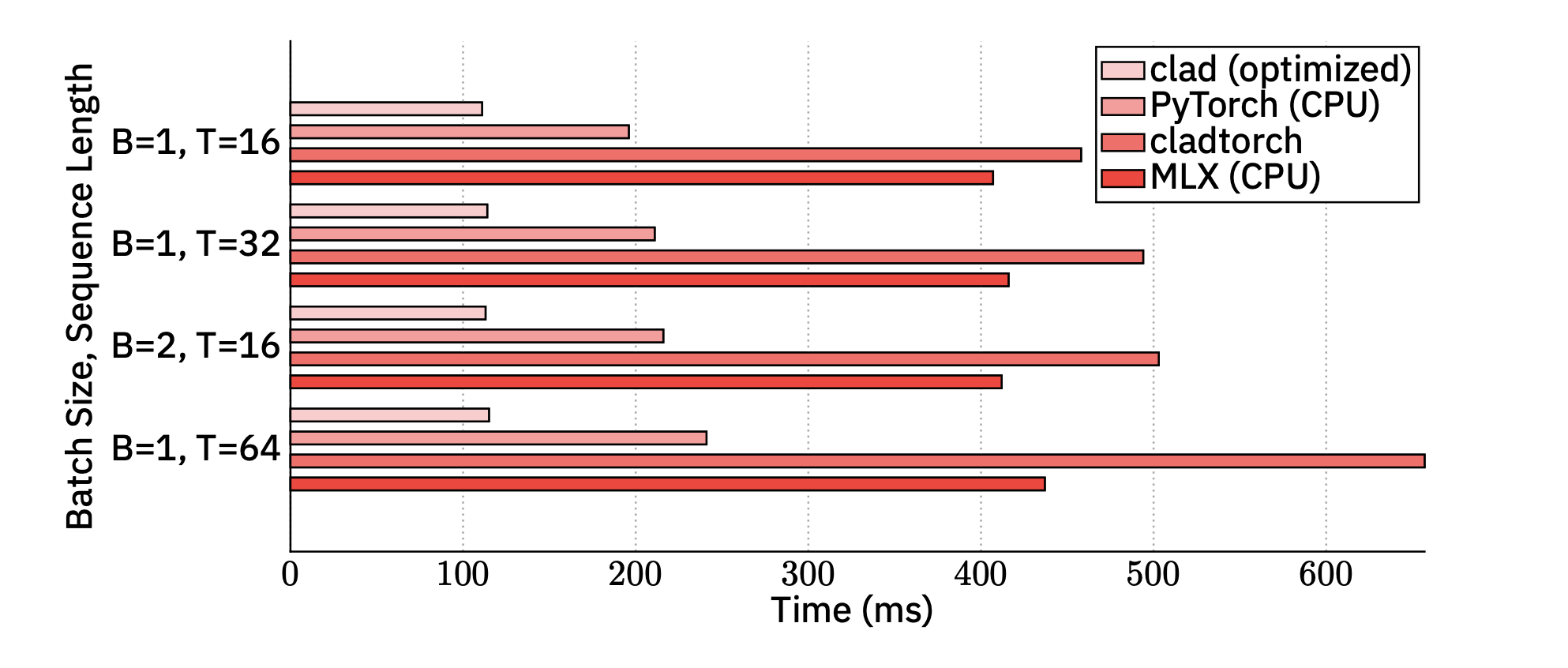
Key Findings: Our implementation was consistently faster than PyTorch on CPU (benchmarked on M4 apple silicon), with speedups approaching 2x. This proves that a compiled, C++-first approach can surpass even the highly tuned PyTorch engine in a CPU-only environment.
The speedup stems directly from our design choices:
-
Zero Python Overhead: The entire training loop is a single, compiled binary. There is no Python-to-C++ context switches and no dynamic dispatch overhead. The compiler sees and can statically optimize the whole program (including the entire backpropagation graph).
-
Cache-Friendly Memory Layout: The single pre-allocated buffer ensures that model parameters and activations are laid out contiguously in memory. This improves cache line utilization and minimizes expensive fetches. Critically, it also eliminates the overhead from freeing and reallocating temporaries that more RAII-based C++ designs incur.
-
Direct Hardware Access: We call optimized BLAS libraries (such as Apple Accelerate) directly for
cblas_sgemmwithout any framework abstraction layers. The stateless kernels also open the door for manual kernel fusion, further reducing memory bandwidth pressure.
Key Achievements & Impact
- Delivered Two Functional Implementations: A flexible
cladtorchprototype and a high-performance C-style engine, providing a comprehensive study in design trade-offs. - Validated Clad for Complex ML: Successfully demonstrated end-to-end differentiation of a production-level GPT-2 model, showcasing Clad’s readiness for real-world compiler research applications.
- Surpassed PyTorch on CPU: Achieved a significant performance milestone, proving the viability of compile-time AD for high-performance ML.
- Created a Research Foundation: The optimized, kernel-based architecture provides an ideal base for exploring GPU acceleration and novel compiler optimizations.
This project also illustrates the trade-off between developer ergonomics and raw speed. While cladtorch’s PyTorch-like API was pleasant to use, its abstraction overhead was fundamentally at odds with peak performance, and would require significant work to bring to the same level of performance as PyTorch itself. The C-style engine, though less “modern C++,” is what allowed us to beat PyTorch.
Future Work & Next Steps
The project’s architecture opens several interesting avenues to explore further:
- GPU Acceleration: The stateless, pointer-based kernel design is a good candidate for porting to CUDA. This will let us test our hypothesis on the hardware where training is done at scale.
- Clad-Driven Kernel Fusion: We can leverage Clad’s static analysis to automatically fuse sequences of operations (e.g.,
softmax+cross_entropy) into single, more efficient kernels, reducing memory bandwidth and kernel launch overhead.
Conclusion
This GSoC project aimed to explore whether compiler-level AD could make LLM training more efficient in C++ environments. Our implementation demonstrates clear performance improvements over PyTorch on CPU, while also highlighting important trade-offs in C++ ML system design. By deeply integrating with the compiler via Clad, we’ve demonstrated that compiler-driven ML can even surpass mature Python frameworks. This work provides a tangible, high-performance alternative for C++-centric HPC environments and offers the Compiler Research Group a powerful real-world benchmark for future Clad enhancements.

